

JavaScript SEO Best Practices: All You Need to Know

JavaScript is a term you may hear in the context of various headaches when it comes to technical SEO, although it doesn’t necessarily have to mean that these days. In the early days (i.e. back in around 2008), it was reported that Google had trouble crawling and rendering JavaScript-built websites, with best practice advice at the time being to minimise all use of JavaScript wherever possible.
Things have changed, however, and the web has long since moved on from just plain old HTML. In fact, Google has all but confirmed that it treats JavaScript content no different to other languages and applications.
However, there are a number of things to look out for if you’re dealing with a site that is built using JavaScript or has certain reliance on JavaScript libraries in certain areas. Typical pitfalls come down to crawling, rendering, and eventually indexation and ensuring that Googlebot is able to discover content that is pulled in via JavaScript in the same way that it would on HTML or CSS resources.
From an SEO standpoint, JavaScript does present a slightly different challenge to typical technical SEO troubleshooting and there are some learning curves involved. Among other things, JavaScript can be associated with contributing to page load and performance issues alongside discoverability, and these are things we need to be on the lookout for.

What is JavaScript?
Along with HTML and CSS, JavaScript is one of the core languages of the internet used to execute website code. It uses a number of third-party libraries, with jQuery being the most popular alongside others such as React and Angular. Beyond the styling and structural functions of CSS and HTML, JavaScript allows pages to use interactive elements. Think about the last time you used a site search, a video embed, or a drop-down hamburger menu on a website – all of these would have used JavaScript as a means to execute.
Beyond interactive functionalities dotted around a site, JavaScript can also be used to build almost everything on the site to serve user content, usually on a dynamic basis. Think eBay, Amazon, or another eCommerce site that pulls in content dynamically when certain searches or filtering methods are applied. In terms of identifying JavaScript on a website, using a Chrome plugin such as Wappalyzer will allow you to see if a website was built using a JavaScript library. You can also use “Inspect” in your browser to explore a website’s code, the use of which we’ll delve into further on.
So, JavaScript certainly isn’t a stranger to the web. Most of the time, it doesn’t prevent any major SEO considerations (beyond site speed, perhaps) if it’s used across a site sparingly to serve functionality. If, however, a website is built with heavy JavaScript reliance, there are considerations for dealing with Googlebot. With the increase in the popularity of using JS frameworks on publicly facing front-end websites, it is important to further understand exactly what impact these have when it comes to Googlebot crawling and indexing your site's pages.
Google and JavaScript: how they interact
Despite there being a lot of documentation and guides on the subject, there is a lot of conflicting information about how Googlebot works when crawling and indexing a page from a site using JavaScript. As we’ve already outlined, there’s no need for major panic if you’re working on a predominantly JavaScript-centric site as there are plenty of considerations to make things work. It is true, as Google has confirmed, that Google can crawl and index JS sites. However, there are indeed caveats to explore and be mindful of.
Let’s start at the beginning and take a look at how Googlebot processes JavaScript in order to get a better understanding of the process from their side.
Typically, you will see the Googlebot process being displayed as a simple flow:
Follow the link to discover the page
Read HTML and index
If JS is detected, render and update the index
Delving into this in more detail, here’s a more thorough look at the process from Google’s own documentation:
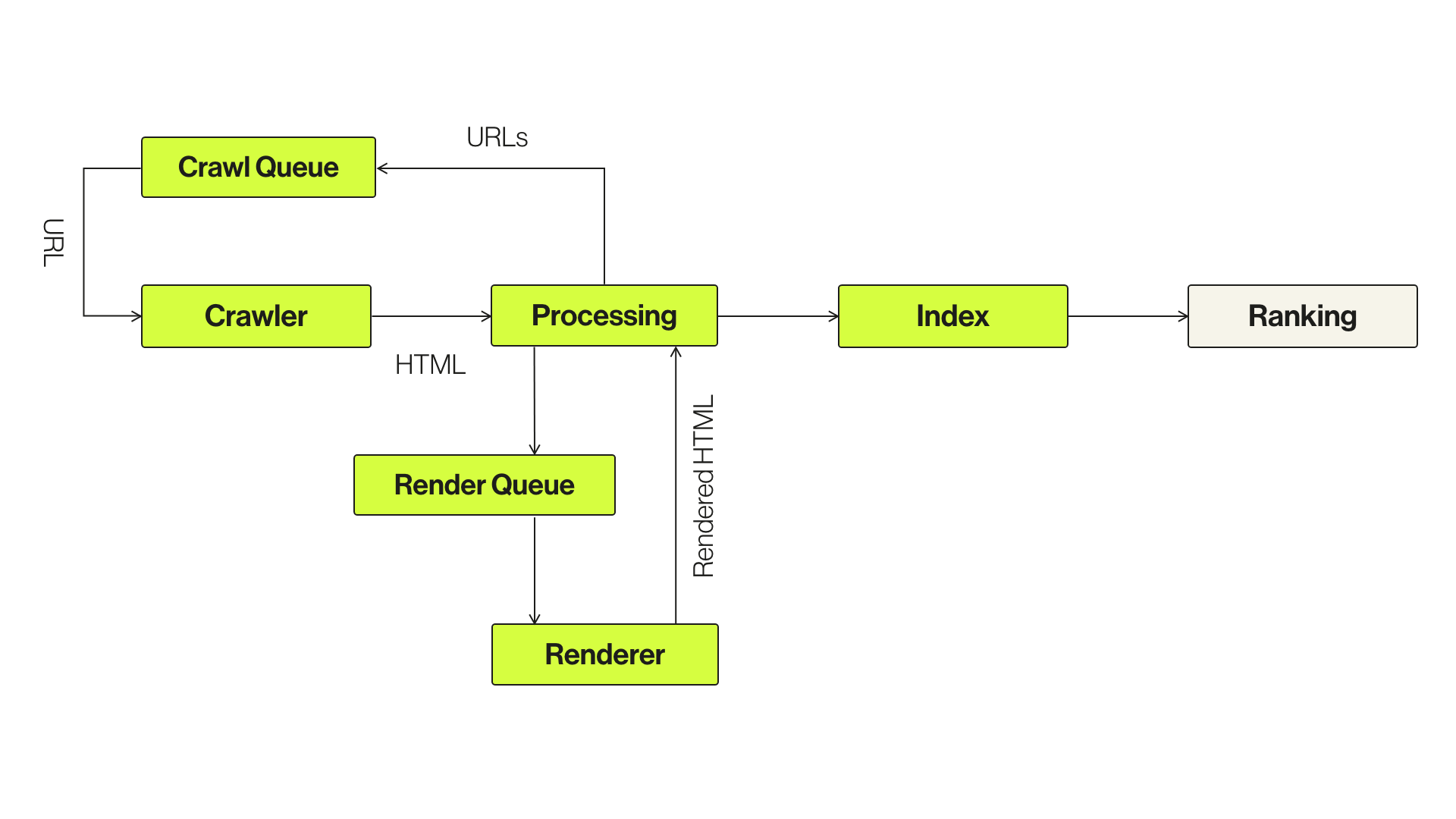 Breaking this down into a step-by-step process, Googlebot will first crawl the URLs crawled in the initial queue. The crawler then sends a GET request to the server, which in turn responds with the headers and contents of the HTML file, and not JavaScript initially, due to rendering resources on Google’s side. This includes elements such as page size, title, description, header tags, links, and content to name a few. JavaScript resources are then queued for processing in the “second wave” of indexing by Google Web Rendering Services (WRS), with Google indexing HTML after the JS is executed.
Breaking this down into a step-by-step process, Googlebot will first crawl the URLs crawled in the initial queue. The crawler then sends a GET request to the server, which in turn responds with the headers and contents of the HTML file, and not JavaScript initially, due to rendering resources on Google’s side. This includes elements such as page size, title, description, header tags, links, and content to name a few. JavaScript resources are then queued for processing in the “second wave” of indexing by Google Web Rendering Services (WRS), with Google indexing HTML after the JS is executed.
The key point here is that websites heavily reliant on JS can be subject to a delay in crawling and eventual indexing, given the resources required to parse and execute from Google’s point of view. This can lead to some problems, particularly around Google’s ability to crawl, render and index websites, understand site structure, internal linking, and various meta elements.
Typical JS Challenges for Googlebot
As we’ve outlined, a number of key challenges for Googlebot during this process can impact the website's ability to perform well in Google’s search results.
For example, Google can index JavaScript on some frameworks much better than others. It’s often down to a case-by-case implementation and how that framework is being deployed. Keep in mind that Googlebot will treat various JS frameworks and builds in different ways. There may be some cases where Google is able to render the content, though depending on configuration it may be unable to crawl internal links built using the framework, depending on how it's built. This can lead to all kinds of issues, notwithstanding the flow of authority to pages in your internal linking journey as well as running into issues around orphan URLs. You may also run into rendering issues that will lead to slower than desired indexation in the context of your render budget.
Here are several more common issues:
Differences in how users see content vs Googlebot
While we are told repeatedly to “optimise for the user”, this doesn’t account for a lot of variables that fall under the technical SEO radar, particularly when looking at JavaScript. Take an eCommerce site for example, where clicking on certain buttons will pull in more buying options and categories, i.e. content. Googlebot won’t click on buttons to access this content on a web page, so you need to make sure it’s discoverable. If your site relies on this type of action to pull content into the page, Google won't see it and render it. The solution here is to ensure that the content is loaded in the DOM without any needed action so that Googlebot does see it.
Google might not fetch every resource
Googlebot and its Web Rendering Service continuously analyse and identify resources that don't contribute to essential page content and may not fetch such resources, so not every resource may be requested. Additionally, if a page doesn’t change much after rendering, Google may decide to not render a page in the future to save on resources. This means that Google may ignore crucial content on your page, which will hinder its ranking opportunity.
Google still can’t see everything
Even though Googlebot runs on the latest version of Chrome, Google has stated that it still can’t see everything. At the Google I/O developer conference in May 2019, Google said: “While Googlebot does run JavaScript, there are some differences and limitations that you need to account for when designing your pages and applications to accommodate how crawlers access and render your content”. Google has created a post on how to fix search-related JavaScript problems, which details further JS SEO-related pitfalls, such as soft 404 errors, among other things.
Potential for pages on new sites to be seen as duplicates
With app shell models (like React), the HTML return on the initial request is often limited and can be the same across all pages. This can cause problems with pages being seen as similar, or as duplicates, and not sent to the rendering queue.
All of this means that it's not a straightforward and consistent process for Google to crawl, render, and index JS-based websites. The number of failure points increases significantly, which can impact organic visibility and rankings. Solutions for how to reduce these challenges are discussed below.
How to test if Google can see JavaScript-based content
If you’re encountering a JS-heavy website, your first port of call is to test whether Google is processing it correctly. There are three tests to run to determine this, and we would recommend undertaking all to ensure all your bases are covered.
Google Search Console
It’s probably best to check what Google Search Console is saying. Inspect a URL in the tool by pasting it in the top search bar, in order to answer these questions:
Is the main content being loaded?
Is the navigation visible?
Is the design and layout of the page visible?
Is the page loading without any issues or errors?
You can do this by checking the rendered HTML code in the right-hand side to ensure that Google is picking up all the relevant links, on-page SEO elements, and more. Check the “Screenshot” tab to see if the page is being seen properly in terms of its layout and, finally, check the “More Info” tab and review the error log. It will show a list of JavaScript errors that occurred while rendering the page or a list of blocked resources. From here, further investigation and debugging can be undertaken to determine why certain content or elements didn’t load for Google, outside of things such as resources being blocked due to robots.txt directives.
Inspect the page in Google Chrome
Load your page in question in Google Chrome, then right-click and choose “Inspect”. This will show you the fully rendered HTML version of the code. Within this, you can use CTRL+F to search for content on the page to ensure it’s visible in the code. Further, highlight the element of your page that is utilising JavaScript by right-clicking on it and clicking “Inspect” once more to highlight the code. This will then locate the code you want to examine in your code inspection pane, where you can expand it and find out if elements such as links or titles are present.
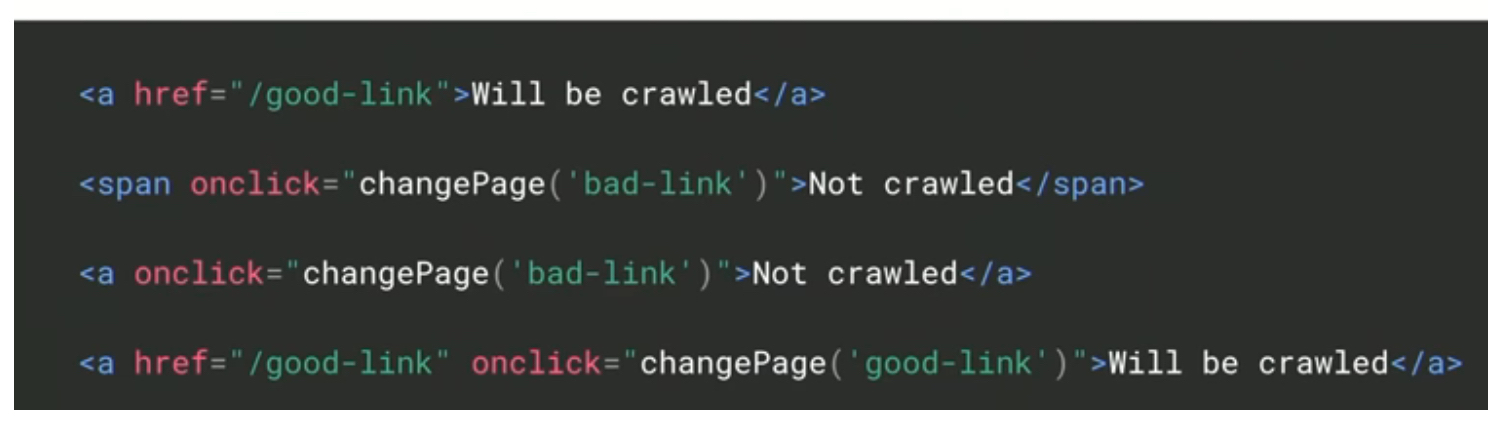
Here, it’s crucial to check whether the links use the correct anchor tags with an href attribute and whether they are marked up correctly. If not, Google won’t be able to crawl or discover these pages. Google can follow links only if they are an <a> tag with an href attribute. Links that use other formats won't be followed by Google's crawlers. Here’s an example of what “good” and “bad” JS links look like:
Check if the content has been indexed in Google
Despite what Google Search Console and your source code may be telling you, it’s probably best to check what is showing up in Google Search itself. Use the Google site search command in Google Search to search whether the URL itself is indexed, and then repeat this process for several sentences across different templates to ensure all the content has been indexed.
It’s important to note that if the page has just been put live, then you may be in the second phase of indexing. If it has been several weeks since you launched the page, this is likely an indicator of crawling issues. If the content cannot be found, it is an indication that Google isn’t processing the JS correctly and further investigation is required.
To summarise:
The crawling, rendering, indexing, and ranking process for a JS website costs Google a lot more in terms of resources to process and understand than it does for general HTML and CSS resources
Even though Googlebot has improved its ability to render JS and understand how content is being pulled in, there are a number of failure points along the way. These include how Google may decide to prioritise a particular resource or even not render a page in the future
Changes to individual pages that are only effective with JS can take longer to be reflected in the SERPs due to a longer queue process.
Google can follow links only if they are an <a> tag with an href attribute. Links that use other formats won't be followed by Google's crawlers.
Generally, in order to ensure that your site is successfully and consistently crawled, indexed and rendered by Google, it’s recommended to find a solution that enables the fully-rendered HTML to be shown to Googlebot. This can be done by looking at options such as server-side rendering and dynamic rendering, which we’ll run through below.
What is dynamic rendering?
Dynamic rendering, detailed here, is also the preferred solution for Bingbot. It enables websites to do the hard work for search engines on the server-side and deliver the rendered version for them. Users still experience the JS version:
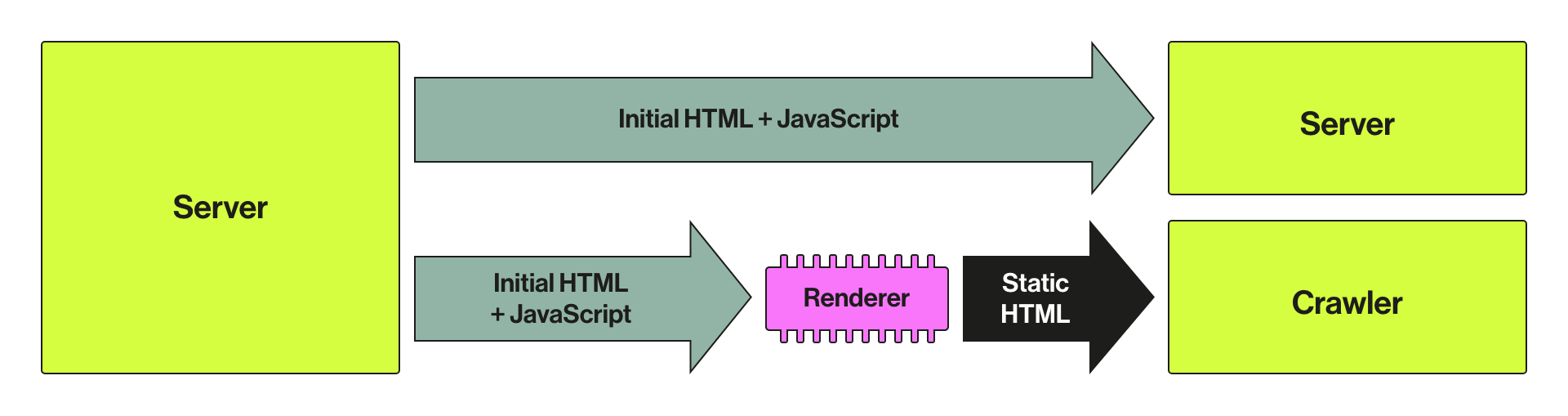
Dynamic rendering is not considered cloaking by the search engines and it ensures they can see all the content and links without having to go through an extensive rendering process. It is good for indexable, JS-generated content that changes rapidly. There are certain tools and/or services that can help with the implementation – Prerender.io, Puppeteer, or Rendertron along with Google’s implementation guidelines.
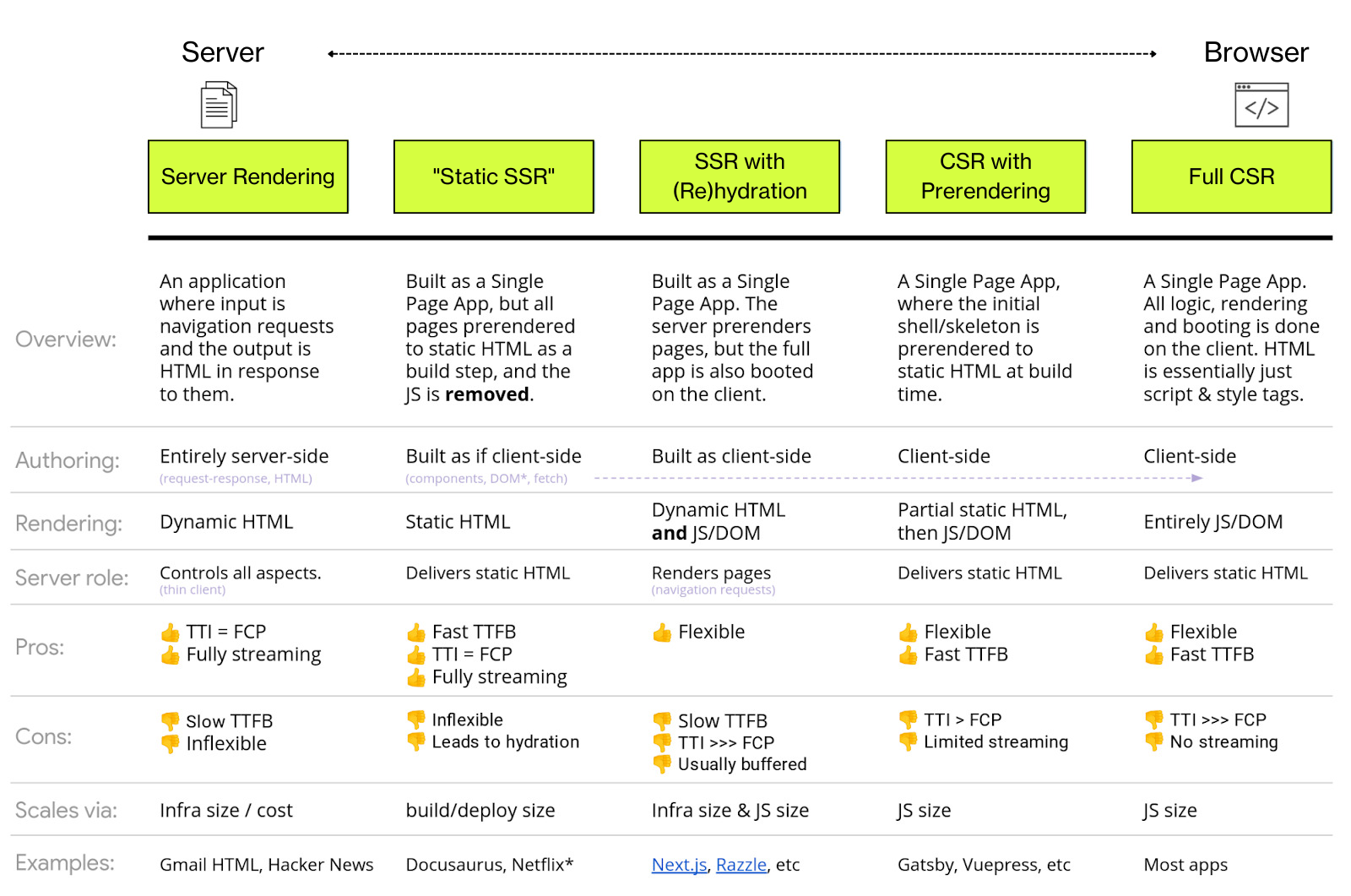
What about server-side rendering?
Server-side rendering (SSR) offers a number of options that can be explored, depending on the application. The chart below from Google highlights these options along with their pros and cons:
Depending on the framework, there are tools that can help with the implementation of server-side rendering:
React – Next.js
Angular – Angular Universal
Vue.js – Nuxt.js
On the plus side, with SSR, all search engines (not just Google) and users are delivered the full code with all the elements needed for SEO. It can also reduce the time taken for the First Contentful Paint, a metric measured by Google for page experience, although it can increase Time to First Byte as everything happens in real-time. However, this is a trade-off worth considering.
What can I do about page speed?
We’ve alluded to this a couple of times during this guide, that being the common association with JavaScript resources dragging down vital page speed metrics. Google, with its recent Core Web Vitals push, incorporates this metric into its toolset and measurement tools such as Lighthouse, and they are metrics routinely looked at as areas of improvement within the industry.
In order to reduce the potentially heavy payload of JavaScript, look at ways in which you can minify your JS resources or, better still, defer non-critical JS resources until the main content is rendered in the DOM. Inlining critical JS across your site can also be an option. JavaScript is an expensive resource for search engines and servers to handle, so always look for ways in which you can minify, compress and streamline your code across your site.
What about other search engines?
This guide has specifically focused on Googlebot, and rightly so given the market share that the search engine has. However, there are other regions where other search engines play a more prominent role and indexing JS needs wider consideration. In terms of rendering JS, you can’t assume what works for Googlebot will work for others – Google is a more advanced search engine with a more advanced crawl, rendering and indexing engine.
As of documentation running up until very recently (with the below chart from Moz from 2017), it remains the case that most other search engines are unable to process JS content.
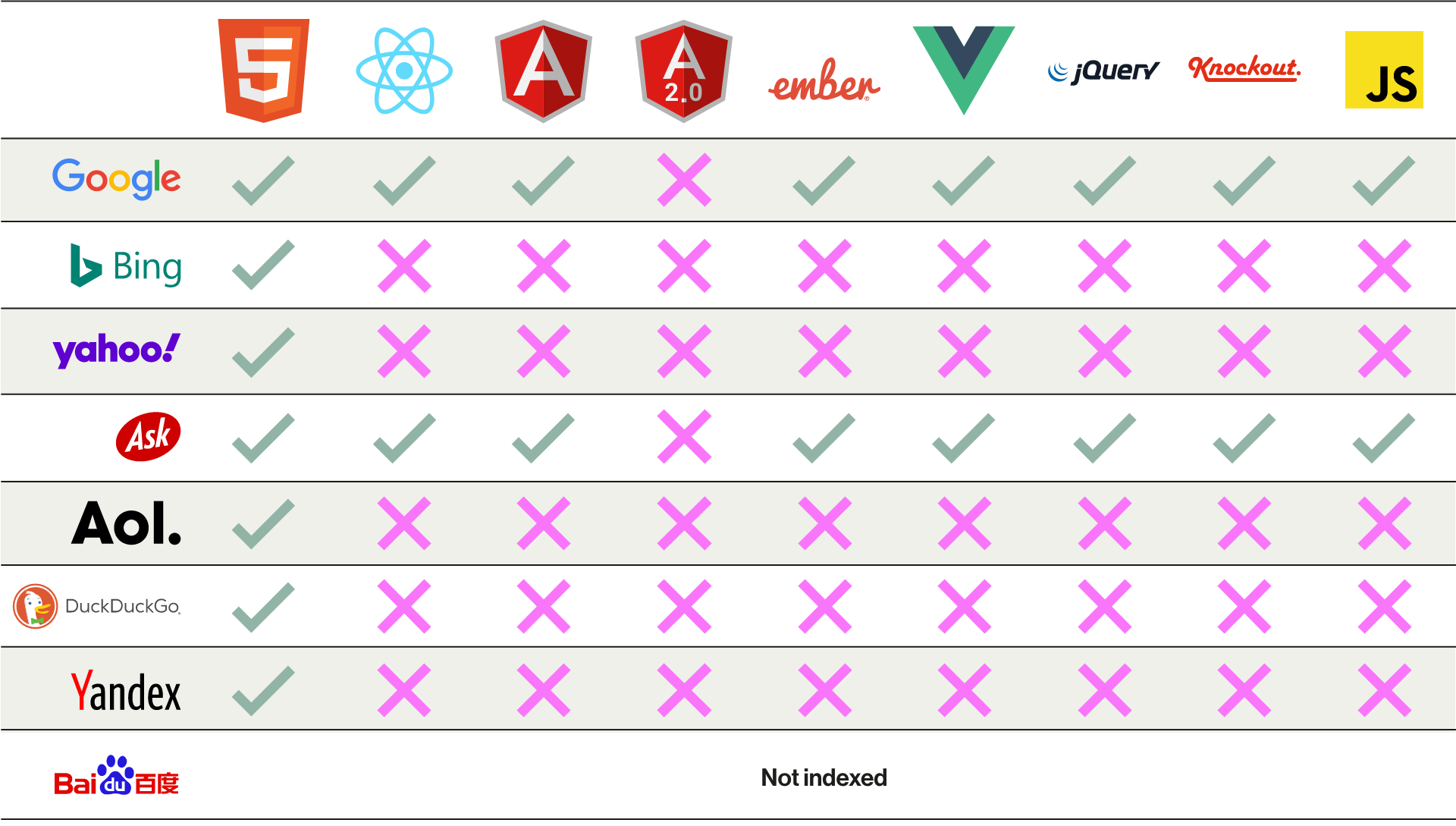
Looking at Google’s closest rival Bing, they themselves direct webmasters relying on JavaScript to a server-side solution, so this may be your safest bet all round.
What should I be asking if my company or client is relying heavily on JavaScript?
Hopefully, we’ve outlined a series of common SEO considerations and pitfalls that come with using JavaScript. Search engines are certainly getting smarter and will only be able to process and render JS-generated content more efficiently in the future. Ultimately, it comes down to ensuring that you’re doing all you can to show as much of the content, structure and linking on your site to Google as possible.
Here are some points to take away:
Understand what your client’s understanding or plans are for serving fully-rendered HTML (DOM) content to browsers and/or search engines.
Understand what your competitors are doing in their JavaScript frameworks and how performance differs. You can ascertain quite a lot on this using a variety of third-party crawling tools.
Get an understanding of the current framework setup and any changes that need to be made to ensure the website is discoverable by search engines. Is moving to server-side or dynamic rendering an option? How are things being discovered by Google as it stands?
How are internal links being discovered and are they being marked up using the correct href links?
Sign-up to Reddico News
To keep up-to-date with the latest developments in the world of SEO, our insights, industry case studies and company news, sign-up here.


